How to Set Up a Perfect ETL Pipeline with AWS Glue

• 10 min
Serverless & Cloud Development Specialist at Fively Passionate about serverless and cloud technologies, I share insights based on my experience. Exploring and advancing modern cloud development.
Get a practical example of setting an ETL pipeline with AWS Glue and integrating the custom classifiers with AWS Glue crawlers by Kiryl Anoshka, the serverless architect at Fively.
Navigating the intricate world of Big Data often leads us to the essential process of Extract, Transform, and Load (ETL), which we discussed in our recent article. In the realm of big data pipelines, ETL orchestration is not just a task, but an art that requires precise coordination of multiple tools and operations.
That's where AWS Glue steps in as a game-changer, offering a streamlined approach to orchestration. In this guide, I will help you explore the nuances of setting up an effective ETL pipeline using AWS Glue workflows and triggers, grounding on my solid experience as a serverless data architect.

I will also give advice on how to integrate the custom classifiers with AWS Glue crawlers for handling fixed-width data files. Let’s dive in, and unravel the intricacies of perfecting an ETL pipeline with AWS Glue step by step together with me.
What Is AWS Glue?
Let’s start with the basics. At its core, AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it effortless for users to prepare and load their data for analytics. Picture it as a smart assistant that handles the heavy lifting of data preparation, allowing you to focus more on the analysis part.
In other words, it is a serverless data integration service that enables the discovery, preparation, and combination of data from various sources for further analytics, machine learning, or application development.
It provides both a visual interface and code-based interface to author ETL jobs, manages the underlying compute resources automatically, and scales to match the workload. AWS Glue is equipped with a metadata repository known as the AWS Glue Data Catalog and an ETL engine that generates Python or Scala code for your data transformation tasks.
Thus, by using AWS Glue, businesses can eliminate the need for complex hand-coded ETL scripts. as it provides tools for automating much of the process of ETL job creation, making data readily available for analytics and freeing up valuable time for data scientists and engineers.
What Are the Main Components of AWS Glue?
At its core, it comprises several key components, each designed to streamline various aspects of the data integration process. Here's a closer look at these main components:
- AWS Glue Crawler: it is used to scan various data stores to automatically infer schemas and create metadata tables in the AWS Glue Data Catalog, which is further used in ETL jobs. Essentially, Crawlers facilitate the process of understanding, organizing, and categorizing your data, making it easier to manage and utilize within the AWS ecosystem.
- Data Catalog: it is the brain of the operation, acting as a central metadata repository, which organizes data from various sources in a way that's easily searchable and accessible. The Data Catalog provides a unified view of all your data assets, making it simple to manage and discover data across AWS data stores.
- ETL Engine: it is designed to process vast amounts of data quickly and efficiently. This engine can automatically generate code in Scala or Python, facilitating the transformation of raw data into a format suitable for analysis. It simplifies the ETL process, reducing the need for manual coding.
- Flexible Scheduler: the scheduler is more than just a timing tool. It expertly handles dependency resolution, job monitoring, and automatic retries. This component ensures that ETL jobs are executed in the right order and at the right time, handling any errors or dependencies with minimal intervention.
- AWS Glue DataBrew: one of the newer additions to AWS Glue, DataBrew, offers a visual interface that simplifies the task of cleaning and normalizing data. It's a powerful no-code solution for complex data transformations, for users who prefer a more graphical approach to data preparation instead of a classical ETL engine. It enables them to perform complex data transformations without writing any code.
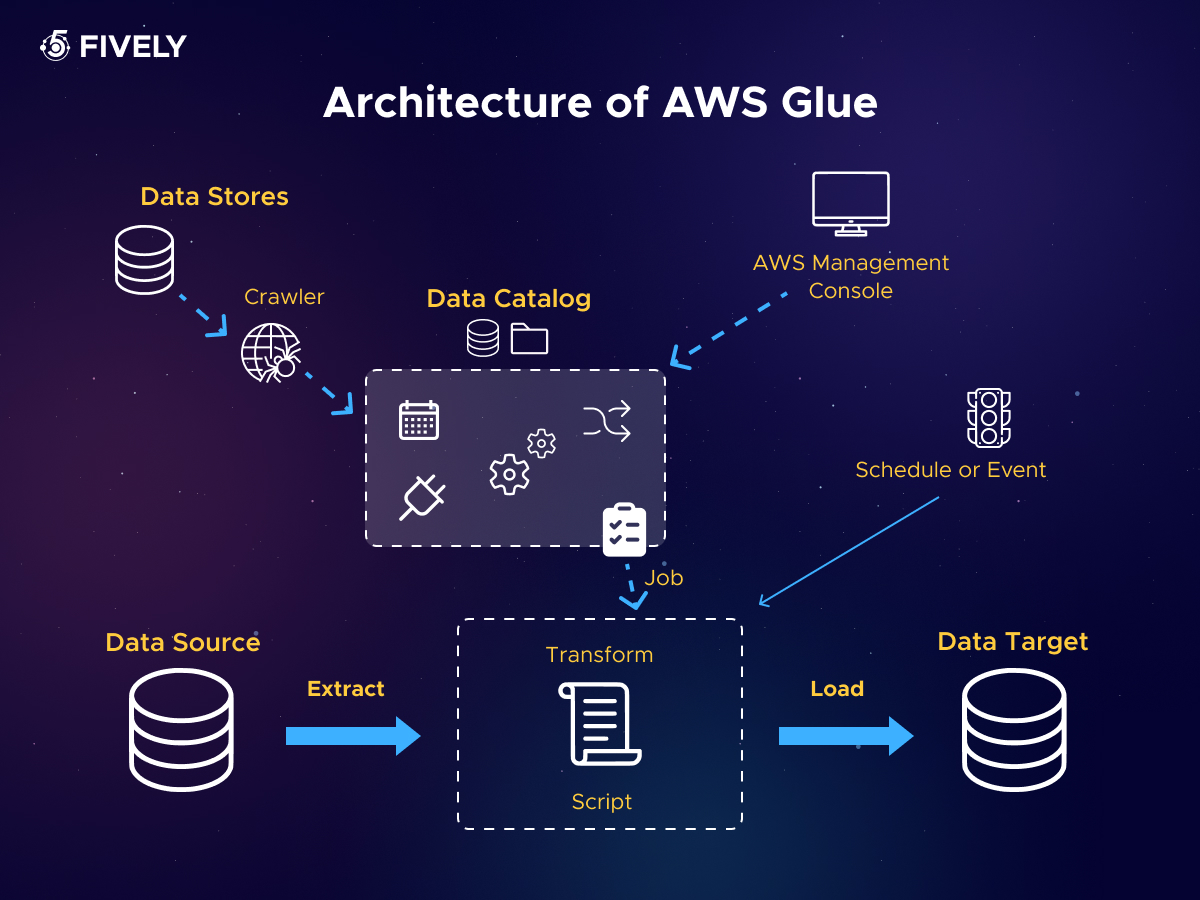
From data discovery and categorization to cleaning, enriching, and moving data, AWS Glue makes it much easier for you to focus on what's really important – analyzing and deriving insights from your data.
Each component of AWS Glue plays a critical role in ensuring a smooth and efficient data integration process, allowing businesses to harness the full potential of their data assets.
What Is the AWS Glue Data Catalog?
Okay, now let’s look deeper at the AWS Glue Data Catalog we mentioned in the previous section. It is essentially a modern metadata repository, designed to be your central source of truth for all your data assets. It's where you store and retrieve metadata information about your data, making it a crucial component in managing data within the AWS ecosystem.
Just think of the Data Catalog as a digital librarian that organizes and provides detailed information about your data: it stores metadata like table definitions, data formats, and their physical storage locations. This allows you to add meaningful business context to your data and keep track of how it evolves over time.
The Data Catalog is fully compatible with Apache Hive Metastore, seamlessly integrating with Big Data apps running on Amazon EMR. It replaces the need for a separate Hive Metastore, simplifying the data management process.
But, beyond this, the Data Catalog offers built-in integration with several other AWS services, including Amazon Athena and Amazon Redshift Spectrum. This integration means that once your data tables are defined in the Data Catalog, they can be accessed for ETL processes and queried directly in services like Athena, EMR, and Redshift Spectrum, creating a unified and consistent view of your data across different AWS services.
What Is the AWS Glue Schema Registry?
The AWS Glue Schema Registry is a key feature that offers a serverless solution for managing the structure of your streaming data. It is designed to bring order and efficiency to the way streaming data is managed, particularly in complex systems where data structure and consistency are paramount, as it allows you to define, manage, and enforce schemas for your data streams, ensuring data consistency and reliability in real time.
It’s like a blueprint for your data: it defines the structure, format, and types of data that your streaming apps can handle. By using the Schema Registry, you can register your schemas in popular data formats like Apache Avro and JSON Schema. The best part? This added layer of data management comes at no extra cost.
Here's an example to illustrate its use: imagine you have a data streaming app developed for Apache Kafka or Amazon Kinesis Data Streams. By integrating it with the AWS Glue Schema Registry, you're not just streamlining your data streams. You're also ensuring high data quality and protecting your system from unexpected schema changes.
How? Through compatibility checks that oversee the evolution of your schemas. This means any changes in the data structure are monitored and validated against the registered schema, preventing potential data inconsistencies or errors.
Moreover, the Schema Registry's integration doesn't end with streaming applications. It extends to other Java applications and services like Amazon MSK, Apache Flink, Amazon Kinesis Data Analytics for Apache Flink, and AWS Lambda. This wide-ranging compatibility ensures that regardless of the platform you use for your data streaming, the Schema Registry can seamlessly fit into your architecture.
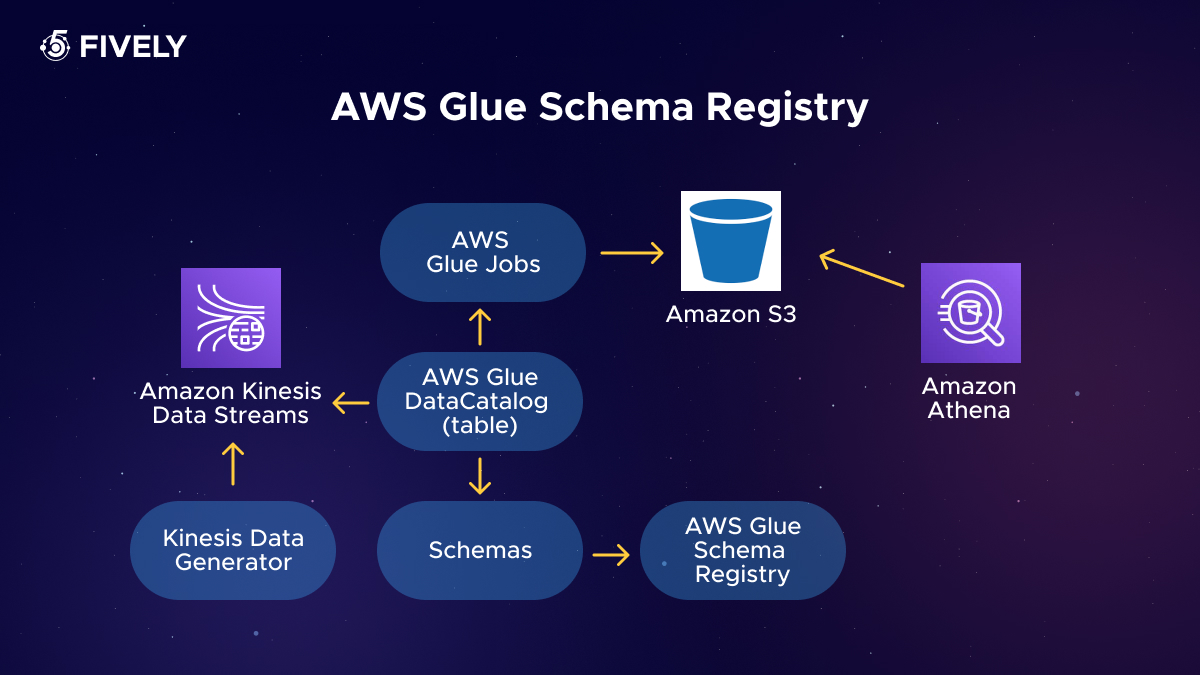
In practical terms, this feature allows you to create or update AWS Glue tables and partitions using Apache Avro schemas stored within the registry. This capability further simplifies the process of managing streaming data and ensures that your data storage structures are always aligned with your current data schema.
Setting Up an ETL Pipeline With AWS Glue: a Practical Use Case & Solution Overview
Now, let’s look at a practical example of setting up an ETL pipeline with AWS Glue.
Let’s suppose we have users' data in the database (AWS RDS) and users' click information in CSV files (in the S3 bucket). These are the steps to transfer them to Tableau for visualization:
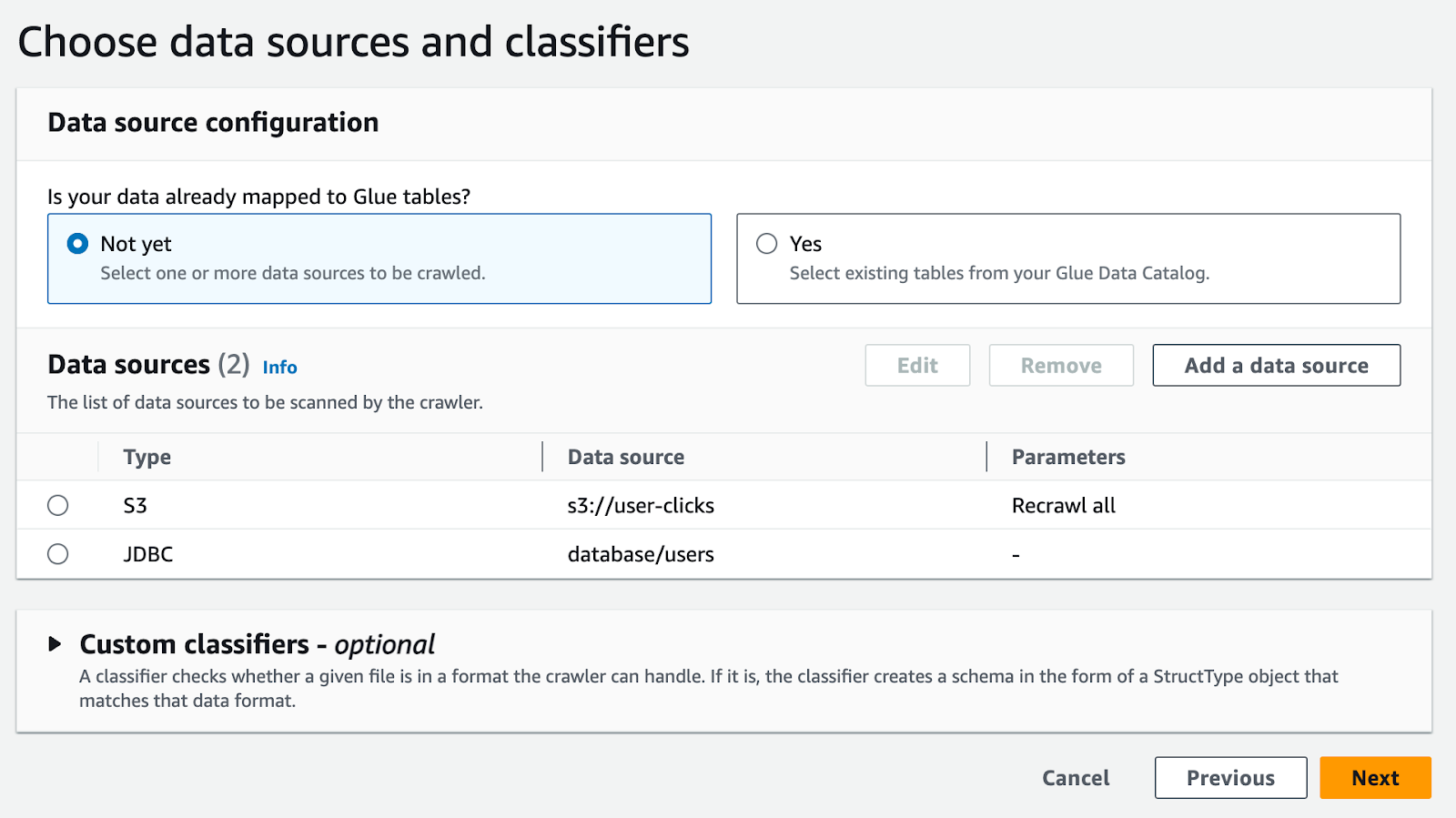
1. Setting Up AWS Glue Crawler (Data Sources are S3 and DB)
First, you should choose your data source and classifiers:
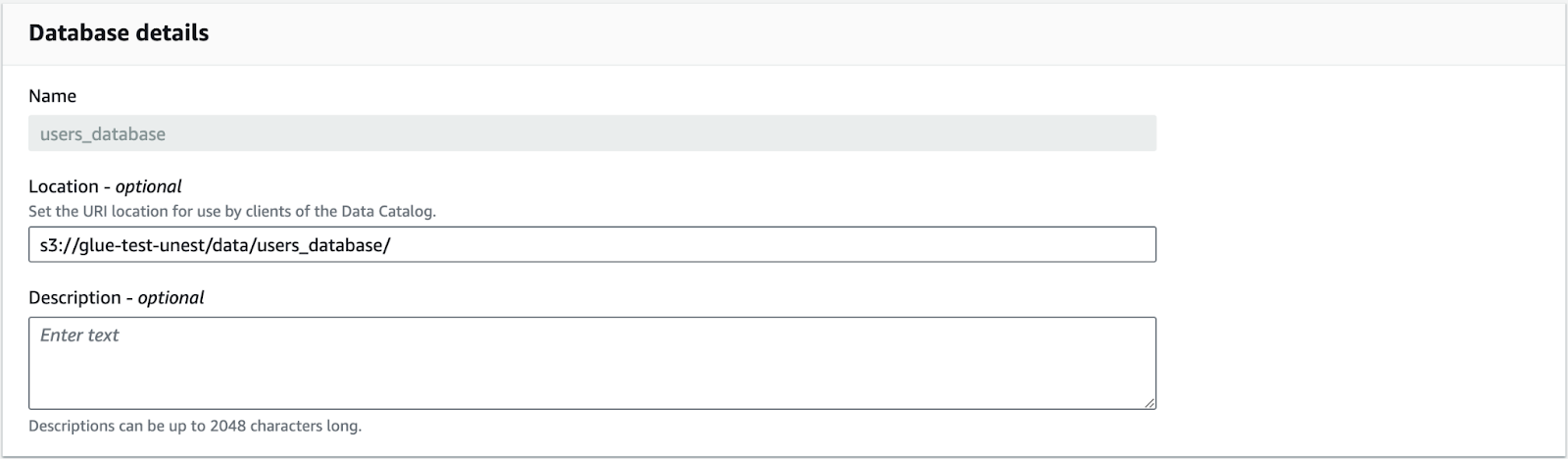
2. Create an output database
In the location, you should specify the path of the output files.
Then, specify Crawler frequency (default is by demand but you can choose any schedule):

3. Create an ETL job
Using Visual Editor we specify two Data Sources and set up the Transformations we need. At the end, we can apply some mapping and save it to our target S3 bucket that will be used by Tableau later:

4. Schedule ETL Job
Now we can set up a schedule for our Glue Job with any frequency:

5. Connect Tableau to the Data
Now in Tableau, we can use AWS S3 Connector to fetch data from our regularly updated S3 bucket and visualize it. Here's a step-by-step guide on how you can do it:
- Open Tableau Desktop
Start by launching Tableau Desktop.
- Connect to AWS S3
In the 'Connect' pane, find 'To a Server' and select 'Amazon S3'. Enter your AWS Access Key ID and Secret Access Key to authenticate.
- Locate Your S3 Bucket
Once connected, you will see a list of S3 buckets. Navigate to the bucket that contains your data using the needed bucket name, and IAM user credentials.
- Select Data File
Choose the specific data file you wish to visualize. Tableau can connect to various file types stored in S3, like CSV, JSON, etc. If your data is spread across multiple files, consider consolidating them into a single file for easier analysis, or use wildcard search if applicable.
- Import Data
After selecting your file, Tableau will import the data. If needed, use the ‘Data Source’ tab for data preparation like joins, cleaning, etc.
- Navigate to Worksheet
Click on ‘Sheet 1’ to begin creating your visualization.
- Create Your Visualization
Utilize the ‘Rows’ and ‘Columns’ shelf to drag and drop fields and start forming your visual. Adjust the chart type using the 'Show Me' panel for better representation.
- Customize Your Visual
Use the ‘Marks’ card for customizing aspects like color, size, and labels. Apply filters or drill-downs for detailed analysis.
- Adjust Fields (Optional)
Right-click to rename any field for clarity.
- Save and Refresh Data Regularly
Save your workbook for future use. To ensure you’re viewing the latest data, set up a refresh schedule if using Tableau Server or Tableau Online, or manually refresh when using Tableau Desktop.
- Publish Your Visualization (Optional)
Share your insights by publishing the workbook to Tableau Server or Tableau Public.
- Stay Updated
Since your S3 bucket is regularly updated, consider checking for data updates frequently to keep your visualizations current.
Tableau is powerful - you can add more data sources, create dashboards, and explore advanced analytics options. By connecting Tableau with your AWS S3 bucket, you can effectively visualize and analyze your data, gaining insights that can drive informed business decisions. Also, please remember to handle AWS credentials securely and manage access appropriately.
***
In this article, we explored the nuances of setting up an effective ETL pipeline using AWS Glue workflows and triggers, using some theoretical base and a small practical example. I hope the insights provided will help you on the path to your own ETL endeavors.
Remember, the integration of custom classifiers with AWS Glue crawlers for managing fixed-width data files can significantly streamline your data processing tasks, ensuring a more robust and effective pipeline. The field of data engineering is always evolving, and staying updated with the latest trends and tools is crucial. Keep exploring, experimenting, and don't hesitate to reach out to us for professional guidance when needed!

Need Help With A Project?
Drop us a line, let’s arrange a discussion
Frequently Asked Questions
Yes, it has a user-friendly UI for crafting AWS Glue jobs to handle your data processing needs. When you define your data sources and the transformations they should undergo, AWS Glue Studio automatically generates the necessary Apache Spark code based on your visual setup, making it accessible even for those without extensive coding experience.
AWS Glue supports both Python and Scala for writing ETL code. This flexibility allows you to choose a language that best suits your team’s skills and project requirements.
AWS Glue offers built-in error handling with retry logic for transient issues and error logging for diagnosis that automatically manages common errors encountered during ETL jobs. Plus, it allows you to customize error handling relaying all alerts to Amazon CloudWatch, so you can set up various actions to be activated in response to specific notifications. For instance, AWS Lambda functions can be triggered upon receiving success or error alerts from AWS Glue.
No, it's not mandatory to use both the Data Catalog and AWS Glue ETL together. Although using them in tandem offers a comprehensive ETL experience, you have the flexibility to use either the Data Catalog or AWS Glue ETL independently to fit the specific needs of your project or workflow.













