Data Pipeline vs. ETL: How to Streamline Your Data Flow

• 10 min
I'm a content specialist at Fively keen on writing fresh articles that can help out business and tech specialists. I love to conduct research, hold interviews, and spotlight sophisticated tech issues.
Discover what is data pipeline and ETL, how these two concepts differ, what is ELT, and which data management approach is better to choose for your company needs.
In today’s data-driven world changing at a turbo speed, the way we process and analyze our data is crucial. Such well-known methods as Data Pipeline and ETL (Extract, Transform, Load) are the fundamental ways of managing data that anyone in the field of data engineering and software development must grapple with.
While both play pivotal roles in data strategy, they are not the same. In this article, we will help you to distinguish between these two terms, and also advice on how to choose the right one for your data needs. Let’s dive in!

Explaining Data Pipelines
First, let’s concentrate on the data pipeline, as this is a broader concept than ETL. Imagine a data pipeline as a highway system for data. It's an automated process that moves raw data from various sources to a destination where it can be stored, analyzed, and accessed. This highway isn't limited to a single type of vehicle or cargo; it's versatile, moving data in real-time or in batches, structured or unstructured.
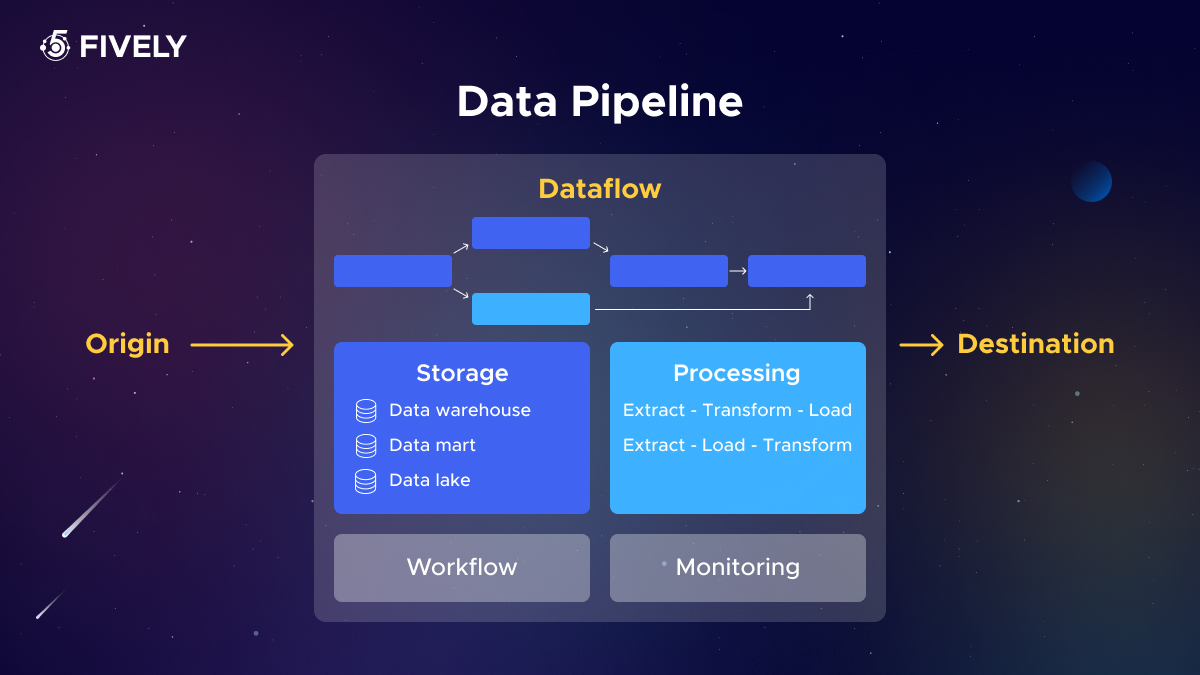
Why the use of data pipelines matters in data management and storage:
- Speed and Efficiency: they enable swift movement of data, making it available for analysis almost immediately;
- Flexibility: they can handle different data formats and structures, adapting as needs evolve;
- Scalability: as data volume grows, pipelines can expand to accommodate the load.
A data pipeline's endpoint can vary widely, encompassing databases, apps, cloud data warehouses, or even data lakehouses. These systems excel at gathering data from a variety of sources, efficiently structuring it for thorough and effective analysis.
How Data Pipelines Are Used in Business Operations?
Data pipelines play a pivotal role in the modern data ecosystem, enabling businesses to efficiently harness and analyze data from various sources. These pipelines are especially valuable for entities that manage numerous isolated data silos, need real-time data analysis, or operate with cloud-stored data.
Here are a few examples and use cases where data pipelines demonstrate their utility:
- Predictive analysis for future trends: data pipelines can execute predictive analysis to anticipate future market trends or customer behaviors, providing invaluable insights for strategic planning;
- Supply chain optimization: in a production context, data pipelines can forecast when resources might deplete, helping in proactive resource management. This can extend to predicting supplier-related delays, ensuring a smoother supply chain;
- Enhanced operational efficiency: By leveraging data pipelines, a production department can streamline its operations, reducing waste and optimizing processes;
- Real-time data insights for decision making: Businesses that depend on real-time data for quick decision-making find data pipelines indispensable. These tools provide up-to-the-minute insights, crucial in fast-paced sectors like finance or e-commerce;
- Cloud data management: For organizations with cloud-based data storage, data pipelines facilitate efficient data transfer, transformation, and analysis across cloud platforms;
- Customer experience enhancement: By analyzing customer interaction data across multiple touchpoints, data pipelines can help tailor personalized experiences, increasing customer satisfaction and loyalty;
- Healthcare data analysis: In healthcare, data pipelines can integrate patient data from various sources for more comprehensive care delivery and research.
Thus, data pipelines, with their versatile applications, are not just a technological innovation but a cornerstone of data-driven decision making in modern businesses.
ETL Explained
Now, let’s proceed to the ETL concept. ETL stands for Extract, Transform, and Load, and it encapsulates the essential processes used in data warehousing to prepare and transport data for effective usage.
It is the traditional process used to gather data from multiple sources, reformat and clean it up, and then deposit it into a data warehouse. It's like a factory assembly line where raw materials (data) are refined and packaged into a finished product (information).
Let's figure out what this means:
- Extraction: This is the initial phase where data is gathered from heterogeneous sources, which could range from traditional databases, like SQL or NoSQL, to files in various formats, or even cloud services that aggregate data from marketing tools, sales platforms, or operational systems.
- Transformation: Here, the extracted data undergoes a metamorphosis, changing shape or form to align with the target destination's requirements. This might involve cleansing, aggregating, summarizing, or reformatting the data.
- Loading: In the final leg of its journey, the data arrives at its new home, be it a structured database, a centralized data warehouse, or modern cloud-based data repositories from providers like Snowflake, Amazon RedShift, and Google BigQuery, ready for analysis and business intelligence activities.
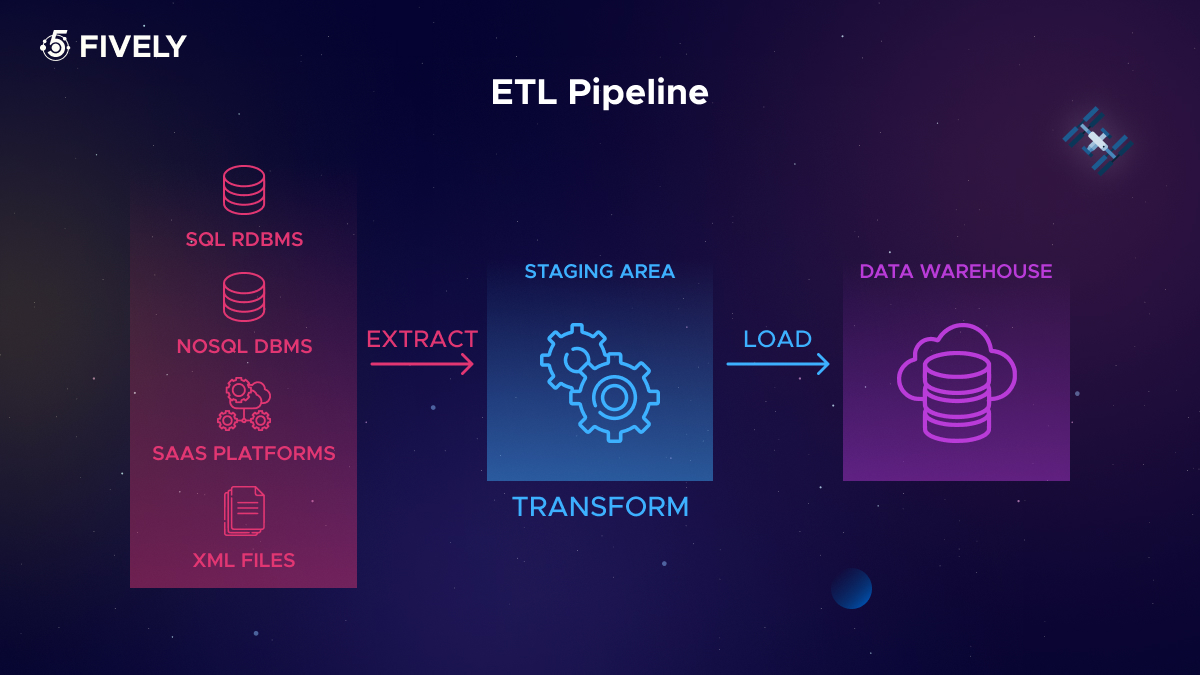
The significance of using the ETL method in data management can’t be overestimated:
- Data integrity: the transformation phase ensures that the data is consistent and of high quality;
- Compatibility: ETL standardizes data into a format that's usable further in data pipelines and across the organization;
- Historical context: storing transformed data allows for historical analysis and the use of business intelligence tools over time.
The endpoint of an ETL process, just like in a data pipeline, is crucially versatile, encompassing a range of possibilities such as databases, applications, and data lakes. These destinations are particularly proficient at gathering data from various origins and structuring it in a manner that facilitates efficient and thorough analysis, essential for drawing actionable insights.
ETL vs. ELT: Two Strategic Data Frameworks
The data management landscape offers two primary pathways for preparing data for analysis - ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform). At a glance, they may seem nearly identical, but the difference lies in the sequence and strategy of data preparation.
ETL is the classic approach where data transformation occurs before loading. It's a premeditated process suitable for scenarios where the data usage patterns are well-defined and consistent. By transforming data upfront, it's primed and ready for specific business intelligence needs upon entering the data warehouse.
ELT, on the other hand, flips the script, loading data directly into the data warehouse and transforming it thereafter. This approach is gaining traction in environments rich with diverse analytical tools, offering the agility to mold data to various analytical demands on an ad-hoc basis.
The ETL process is perfect for small data sets that require complex transformations, while for larger, unstructured data sets and when timeliness is important, the ELT process is more appropriate.
Let’s look now at how these two similar data management approaches compare in various parameters, such as data preparation, infrastructure needed, speed, scalability, and other:
Though ETL and ELT may differ in their processes and methodologies, they both converge on a singular goal: to optimize and transform data, ensuring it is primed for insightful analysis and strategic decision-making.
How ETL Pipelines Are Used in Business Operations?
ETL pipelines serve as the backbone of data-driven decision-making, offering a unified view of an organization's diverse data landscape. These pipelines are instrumental in aggregating data from disparate sources, thereby providing a cohesive and enriched data ecosystem that powers analytics and strategic insights.
Consider a multinational corporation aiming to harness its global sales data. An ETL pipeline can extract data from various sales platforms, transforming this information to align with the company’s analytical framework before loading it into a centralized data warehouse. This consolidation enables leadership to gauge performance metrics across markets with precision.
Let’s look at some real-world applications of ETL pipelines:
- Data Centralization: Objective: Unify disparate data sources into one accessible repository. Impact: Creates a holistic view of organizational data, enhancing cross-departmental synergy.
- Data Store Synchronization: Objective: Migrate and standardize data across varied internal storage systems. Impact: Streamlines internal workflows, promoting efficiency and clarity in data handling.
- CRM Enhancement: Objective: Integrate external data streams into CRM systems for a comprehensive customer profile. Impact: Deepens customer understanding, enabling personalized engagement and service.
- Business Intelligence: Objective: Transform raw data into actionable insights through advanced analytics dashboards. Impact: Empowers decision-makers with real-time data visualizations and predictive analytics.
By leveraging ETL pipelines, companies can distill complex data into actionable intelligence, fueling growth and competitive advantage. Whether it's a granular analysis of customer behavior or a macroscopic view of global operations, ETL pipelines are pivotal in transforming raw data into strategic assets.
The concepts "ETL pipeline" and "data pipeline" often get used interchangeably, yet there's a clear distinction between them: data pipeline encompasses all data movement strategies between systems, while ETL pipeline is a specific subtype, focused on extracting, transforming, and loading data.
How Is ETL Used in Data Pipelines?
ETL stands as a fundamental component in the architecture of numerous data pipelines. Quite often, data pipelines are designed around the ETL process, forming what is commonly referred to as an ETL data pipeline. This setup is pivotal in harmonizing data extraction, transformation, and loading procedures.
Crucially, while ETL is traditionally seen as a batch process, its role in the modern data pipeline is far more dynamic. Today's ETL pipelines can adeptly support real-time data analysis, evolving into what is known as streaming data pipelines. This adaptation allows for continuous and immediate data processing, which is essential in scenarios where timely data insights are critical – for instance, in financial trading, online retail, or live customer interaction platforms.

By embedding ETL processes within data pipelines, businesses ensure not only the efficient movement of data but also its transformation into a format that's ready for immediate analysis and action.
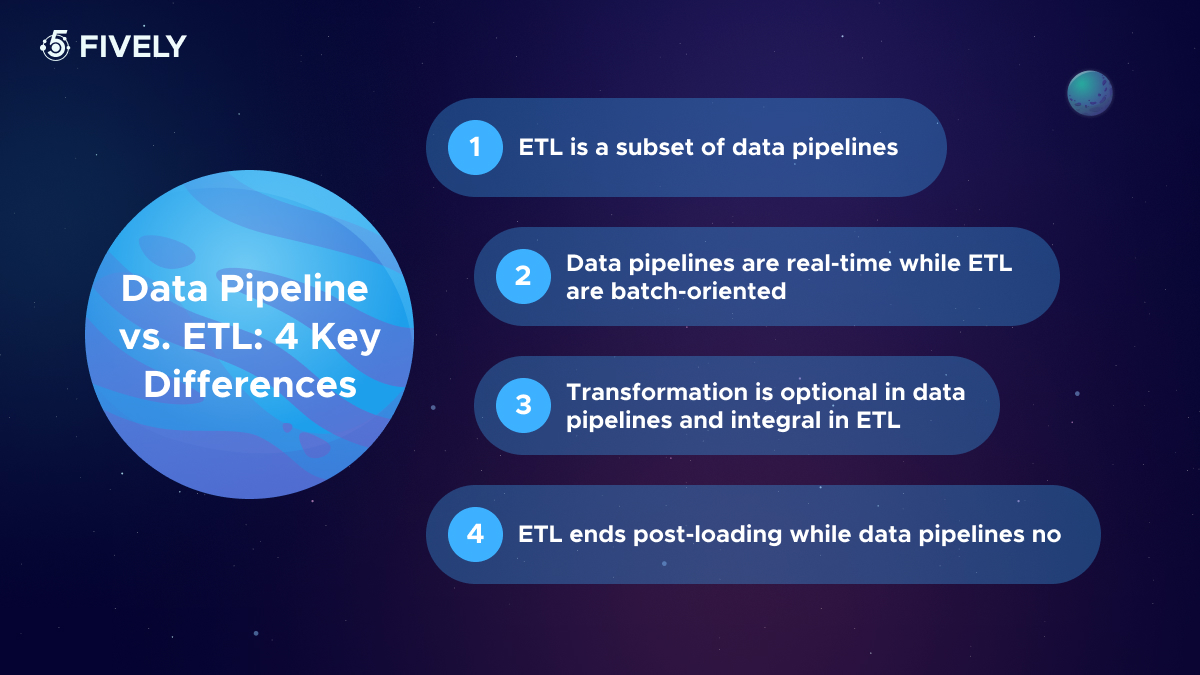
Data Pipeline vs. ETL: 4 Key Differences
Now, we’re ready to compare these two very similar but separate data management methods. While a data pipeline refers to the overall flow of data from source to destination, ETL is a type of pipeline with a specific sequence of processes. I would circle 4 key differences between them:
ETL Is a Part of Data Pipeline
ETL pipelines represent a subset within the expansive domain of data pipelines. While ETL is confined to specific, batch-oriented tasks of data handling, data pipelines encompass a broader range of real-time data processing activities, offering a more holistic solution for diverse and continuous data management needs.
Data Pipelines Are Real-Time While ETL Are Batch-Oriented
Data pipelines are designed for data processing taking place right now, while ETL (Extract, Transform, Load) functions in distinct batches. For scenarios requiring up-to-the-minute reporting and analytics, broader data pipeline systems are employed. These systems facilitate continuous data movement through continuous batches, encompassing both ETL and ELT processes for real-time data flow.
Transformation Is Optional in Data Pipelines and Integral in ETL
In the realm of big data, transformations are often executed as needed, hence not all data pipelines modify data during transit. Data pipelines primarily focus on the movement of data, with transformations happening at various stages, if at all. Conversely, ETL inherently includes a transformation phase before loading data, preparing it for subsequent analysis.
ETL Ends Post-Loading While Data Pipelines No
ETL's role concludes once data is extracted, transformed, and loaded. It's a distinct, finite process within an ETL pipeline, ending after data is deposited into a repository. On the other hand, data pipelines might extend beyond mere data loading. In these pipelines, loading can initiate further actions, like triggering webhooks or activating additional processes and flows in interconnected systems.
Choosing the Right Approach
Driving the line, the isn’t such a thing as the right approach here, cause the choice between a data pipeline and ETL will depend on the specific needs of your business:
- Real-time analytics: Opt for a data pipeline when your business demands instantaneous insights derived from streaming data. Data pipelines excel in handling and processing data in real-time, providing up-to-the-minute analysis that is crucial for time-sensitive decisions and actions.
- Data warehousing: If your primary goal is to construct and maintain a comprehensive data warehouse that serves as the foundation for your analytics, ETL is often the more suitable choice. ETL processes are tailored for batch processing and organizing data in a structured manner, making them ideal for building reliable, query-optimized data warehouses.
- Complex data transformation needs: Choose ETL when your data requires extensive and complex transformations before analysis. ETL processes allow for more intricate manipulation and refinement of data, ensuring that it meets specific formats and standards required for detailed analytical tasks.
- Scalable data integration from multiple sources: If your business involves integrating and processing data from a variety of sources on a large scale, a data pipeline might be the more effective solution. Data pipelines are adept at aggregating and processing large volumes of data from diverse sources, offering flexibility and scalability.
- Cost-effective data management: For businesses looking for a cost-effective approach to managing large datasets without the need for immediate processing, ETL can be a more budget-friendly option. ETL's batch processing nature often requires less computational power compared to the real-time processing of data pipelines.
Both data pipelines and ETL processes are critical in the modern data ecosystem, each serving distinct purposes. As data continues to be an invaluable asset, understanding and utilizing these processes effectively can be a significant competitive advantage.
Consider your options carefully, and remember, in the world of data, one size does not fit all. Whether you opt for the agility of data pipelines or the structured approach of ETL, the key is to align the strategy with your business objectives and data strategy.
At Fively, our expertise extends beyond exceptional web application development. We excel in the realm of data warehousing, ensuring that your data is not just stored, but optimized for insightful analytics.
If you are ready to streamline your data and elevate your software solutions with the analytical power of sophisticated data warehousing, remember that Fively software and data warehouse specialists are always ready to help you. Feel free to reach out to us, and together we'll embark on a journey to develop solutions that surpass your expectations in every way. Let’s fly!

Need Help With A Project?
Drop us a line, let’s arrange a discussion













