Mild Introduction to Modern Sequence Processing. Part 1: Looking into Recurrent Neural Networks

• 7 min
Experienced Software Engineer impassioned by AI, sharing my knowledge with you here
Explore the fundamentals of modern sequence processing with a focus on the mechanics of Recurrent Neural Networks with a top ML specialist at Fively Andrew Oreshko.
Today, everyone is talking about recent advancements in AI, especially about the most popular and frequently used tool ChatGPT. But few know that all these AI breakthroughs could only become possible thanks to the existence of Transformer models. In this series of articles I, as a leading ML specialist at Fively, will tell you about how they make all this magic work, but first, let’s start with their predecessor - RNN.

The Concept of RNNs
Recurrent Neural Networks (RNNs) represent a pivotal milestone in the evolution of deep learning, revolutionizing the way sequential data is processed and understood.
In essence, RNNs are sophisticated architectures equipped with the ability to retain the memory of past inputs, thereby enabling them to capture patterns and dependencies within sequential data.
This unique characteristic has propelled RNNs to the forefront of numerous domains, including natural language processing, time series analysis, speech recognition, and more.
The inception of RNNs marked a significant departure from traditional feedforward neural networks, which lack the capacity to retain information over time. Instead, RNNs introduce recurrent connections that gear them with a form of temporal memory, allowing them to incorporate context and sequential information into their predictions.
This capability has led to groundbreaking advancements in various fields, from generating coherent text (we’ll build a basic text generator at the end of the article, so hang around) to predicting future stock prices and so on.
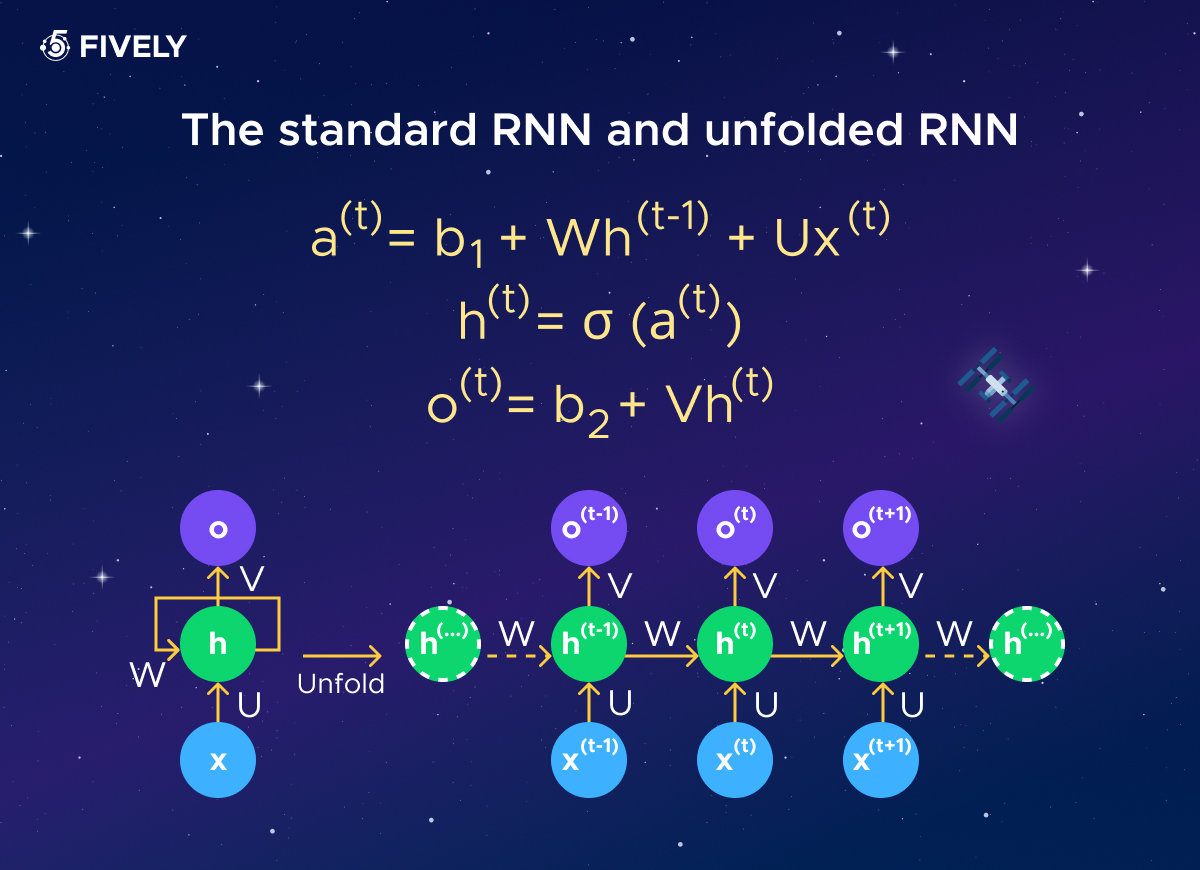
At each time step, the RNN receives an input (token/word/etc). At the beginning, the RNN initializes its hidden state to a fixed value, often a vector of zeros. This hidden state acts as a kind of memory that retains information from previous time steps.
At each time step, the RNN updates its hidden state based on the current input and the previous hidden state. This update is determined by learned parameters (weights and biases) within the network.
In essence, the RNN takes the current input and blends it with the information it has retained from previous time steps to update its memory. The algo of hidden state calculation is represented in the image down below:

These three formulas represent the core Forward Pass logic of the standard RNN i.e. the calculation of hidden state and output (if needed), where the U is the input-to-hidden, V - is the hidden-to-output, and W - is the hidden-to-hidden weight. The sigma (σ) is an activation function of the hidden state. Commonly used functions are sigmoid, hyperbolic tangent, ReLU.
The hidden state acts as a memory that stores information about previous inputs in the sequence. It captures relevant information from past time steps and combines it with the current input to generate an output and update its own state.
Depending on the specific task, the RNN may produce an output at each time step (i.e. in sequence-to-sequence task). This output is generated based on the current hidden state and can be used for various tasks such as video classification on the frame level.
The process repeats for each time step in the sequence, with the hidden state evolving over time as new inputs are processed. The RNN essentially unfolds across time, maintaining and updating its hidden state at each step.
During training, the RNN adjusts its internal parameters (weights and biases) based on the error it makes in its predictions. This adjustment is done through a process called backpropagation through time (BPTT), where gradients are computed and used to update the parameters.
This allows the RNN to learn to capture relevant patterns and dependencies in the data over time. The next article’s focus will be just that – how the training of RNN is happening alongside the math in the background.
 Services Account
Services Account
Diving Deeper Into RNNs Capabilities and Limitations
However, while the basic RNN architecture is elegant in its simplicity, it is not without its limitations. Training RNNs over long sequences can cause problems like vanishing or exploding gradients.
Furthermore, the invention of specialized RNN architectures, such as Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs), has significantly augmented the capabilities of traditional RNNs. These architectures introduce sophisticated mechanisms, such as memory cells and gating units, which enable them to more effectively capture long-term dependencies and mitigate issues like vanishing gradients.
All in all, RNNs suffer from several notable disadvantages:
- Difficulty in capturing long-term dependencies: While architectures like LSTMs and GRUs address some issues with vanishing gradients, they may still struggle to capture dependencies across very long sequences effectively. This limitation can impact the performance of RNNs in tasks requiring the understanding of extensive context.
- Computational inefficiency: RNNs are inherently sequential models, processing data one step at a time. This sequential nature can lead to slower training and inference times, especially when compared to parallelizable architectures like convolutional neural networks (CNNs).
- Sensitivity to input order: RNNs process sequential data in the order it is presented. This means that the model's predictions can be sensitive to variations in the order of input sequences, which may not always be desirable, especially in tasks where the inherent order is ambiguous or irrelevant.
- Limited memory capacity: Despite their ability to retain information over time steps, RNNs still have finite memory capacity. This limitation can become problematic when dealing with sequences that are extremely long or when trying to capture very distant dependencies.
Transformer Models: the Next Step in Sequence Processing
Although, in recent years, researchers have made strides in addressing some of these challenges through the development of alternative architectures and training techniques. Everyone now has heard of Transformer architecture which is backing up the extensively used OpenAI’s ChatGPT.
Transformers process sequences all at once through the mechanism of self-attention, which allows them to capture dependencies between all tokens in a sequence simultaneously.
This is in contrast to RNNs, which process sequences sequentially, one token at a time. Because self-attention is applied independently to each token, all tokens can be processed simultaneously, enabling highly parallel computation.
That is why Transformer models are sort of easier to train – the training can be parallelized on the GPU level. Likewise, self-attention enables us to process sequences in any order, unlike RNN. That's merely a teaser regarding transformers; we'll delve deeper into the topic in one of our upcoming articles.
Services Account
RNNs: a Short Practical Example
At long last, let's ignite the fun and code something! We’ll build a very simple character-level text generator off of complete works of Lovecraft, step-by-step.
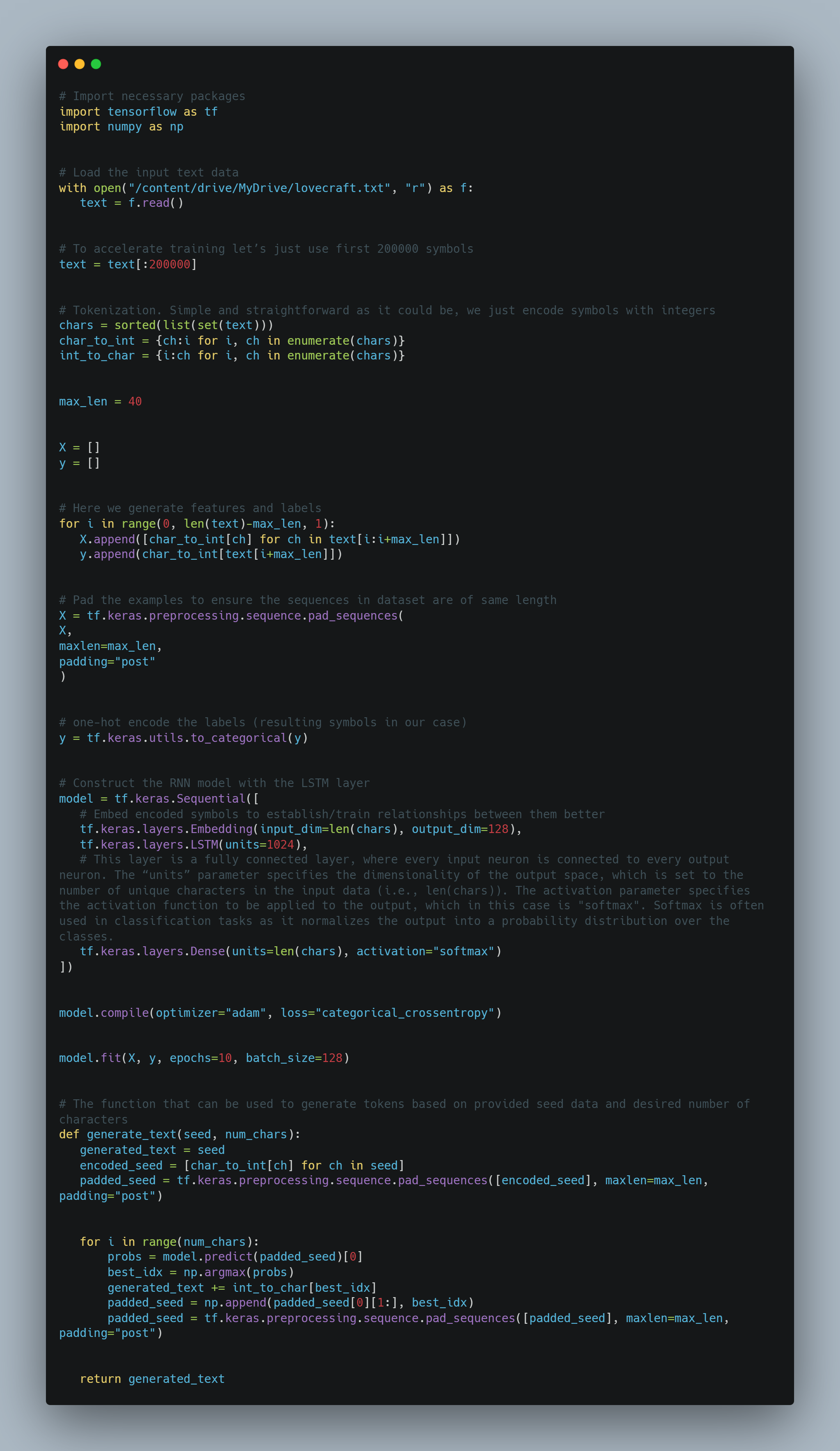
During my experiments with the code above and playing around with all possible hyperparameters I was able to generate the following text:
“Cthulhu isdismissal in disgrace from the subject, and all wondered that he had been swept
away by death and
decomposition. Amidst a wild and reckless throng I was the wildest and more frings of disaster.
Alone I mounted the tomb each night; seeing, hearing, and doing things I must never
reveal. My speech, always susceptible to sense
something of surroundings. Never a
competent navigator, I could now conversed a series of
leaps directly upward in the burgon him would soon
pass, and of the sound no...”
The code showcases how the simple generator can be built with a few lines of Python and the data from the Internet. It is worth mentioning that to build a really robust and impressive model, I’d encourage one to try to fiddle with all possible parameters, like the number of layers, types of layers, number of neurons, activation functions, and so forth. I’d expect rather interesting results.
***
On that note, I’d like to wrap up this small blog post, hope you liked it. Today we’ve introduced the high-level neural network sequence processing things: we’ve had a glance at some forward pass math, and on the tensorflow code to see that all in action. Did you find it useful? Feel free to share your thoughts and contact us in case if you have any questions or need professional ML development and support.
In the upcoming discussion, I aim to explore the inner workings of RNNs, uncovering how they become "intelligent" through training on data. We’ll examine Forward Pass further and will notably learn about Backpropagation/BPTT. So stick around there and let’s learn together!
Services Account
Need Help With A Project?
Drop us a line, let’s arrange a discussion













